¶ Why DPM is not a good solution
Most XBRL creation solutions are based on a DPM (Data Point Model). In this approach, users fill spreadsheets or databases, and after data gathering, the XBRL instance is created.
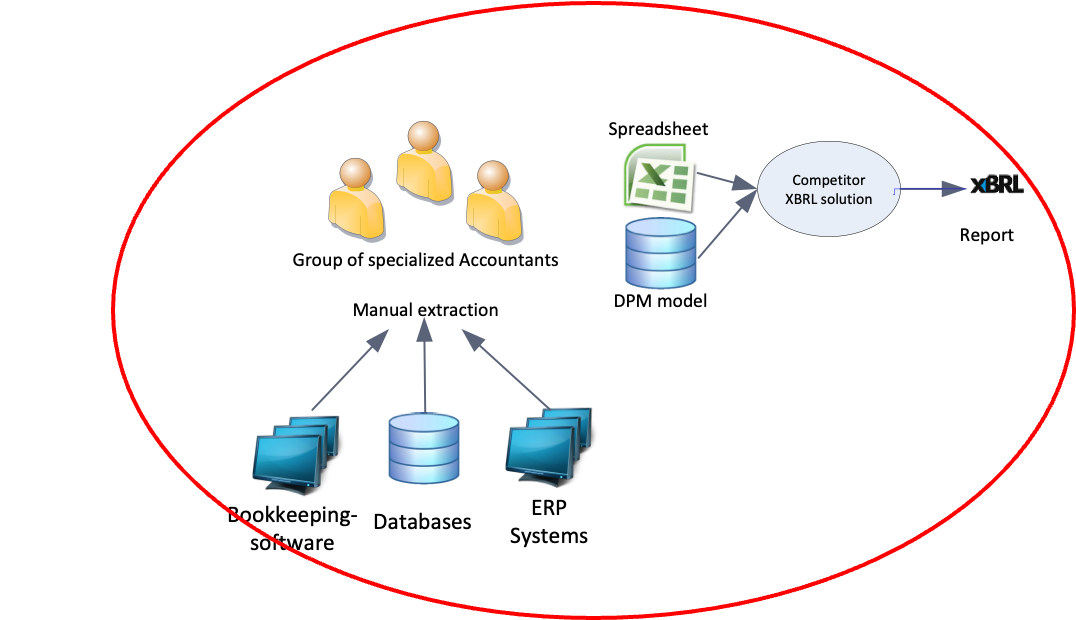
Figure H-1 DPM basd filling of XBRL
If you prefer the DPM approach, you're on the wrong website!
GLOMIDCO takes a completely different approach and philosophy to handling XBRL.
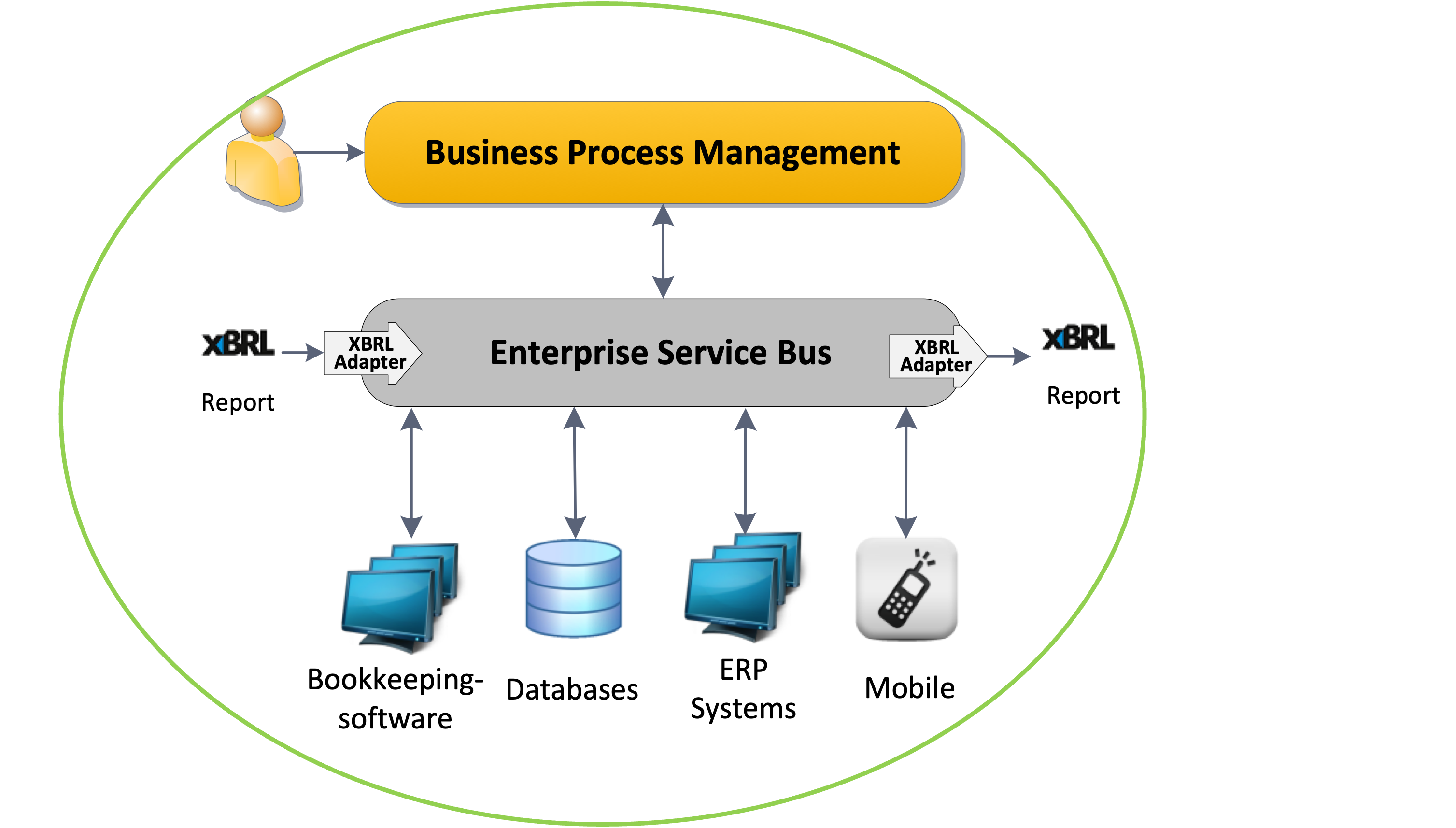
Gigure H-2 GLOMIDCO XBRL processor and mapping capability in practise
DPM has significant limitations compared to GLOMIDCO's mapping-based filling approach:
DPM aaproach vs mapping based solution
¶ 1. Monolithic Architecture Problem
DPM Approach:
Single Massive Transformation:
Business Data → [BLACK BOX DPM] → XBRL Instance
Problems (example applicable for COREP/FINREP):
├─ 60+ tables in one monolithic process
├─ All-or-nothing transformation
├─ Cannot isolate errors
├─ Cannot reprocess individual tables
└─ Cannot partially update
GLOMIDCO Mapping Approach:
Distributed Pipeline:
Business Data → Table 1 Transform → XBRL Fragment
→ Table 2 Transform → XBRL Fragment
→ Table 3 Transform → XBRL Fragment
...
→ Assembler → Final XBRL Instance
Benefits:
├─ ✅ Process tables independently
├─ ✅ Reprocess only failed tables
├─ ✅ Parallel processing possible
├─ ✅ Clear error isolation
└─ ✅ Incremental updates
¶ 2. Complexity and Maintainability
DPM Problems:
Monolithic DPM Mapping:
├─ 60+ COREP tables in single mapping
├─ 40+ FINREP tables in single mapping
├─ Thousands of data point definitions
├─ Complex interdependencies
├─ Difficult to understand
├─ Difficult to maintain
├─ Difficult to test
└─ Difficult to debug
Result: Nobody understands the full mapping!
GLOMIDCO Approach:
Per-Table Mappings:
├─ COREP C 01.00: Own Funds (dedicated mapping)
├─ COREP C 02.00: Capital Requirements (dedicated mapping)
├─ FINREP F 01.01: Balance Sheet (dedicated mapping)
├─ Each mapping is ~500-1000 lines
├─ Each mapping is testable independently
├─ Each mapping has clear inputs/outputs
└─ Total: Manageable complexity
Result: Each team member understands their tables!
¶ 3. Error Handling and Recovery
DPM Limitations:
Monolithic Error Handling:
├─ Error in Table 15 → Entire process fails
├─ Must fix ALL errors before ANY output
├─ Cannot deliver partial results
├─ Cannot isolate root cause easily
├─ Reprocessing = Start from scratch
└─ Long feedback cycles (hours/days)
Example:
Day 1: Run DPM, fails on table 15
Day 2: Fix table 15, run DPM, fails on table 37
Day 3: Fix table 37, run DPM, fails on table 52
Day 4: Fix table 52, run DPM, SUCCESS!
(But could have delivered tables 1-14 on Day 1!)
GLOMIDCO Advantages:
Granular Error Handling:
├─ Error in Table 15 → Only Table 15 fails
├─ Tables 1-14: ✅ Success (delivered immediately)
├─ Tables 16-60: ✅ Success (delivered immediately)
├─ Table 15: ❌ Failed (reprocess only this one)
├─ Clear error context (table-specific)
└─ Fast feedback (minutes, not days)
Example:
Hour 1: Process all tables
- 59 succeed immediately
- 1 fails (table 15)
Hour 2: Fix table 15, reprocess ONLY table 15
- Success! All 60 tables done
(Delivered 59 tables on Hour 1!)
¶ 4. Performance and Scalability
DPM Performance Issues:
Sequential Processing:
├─ Must process all 60+ tables serially
├─ Cannot parallelize (monolithic)
├─ Long processing times (hours)
├─ Resource intensive (GB of memory)
├─ Scales poorly with data volume
└─ Single point of failure
Typical: 2-4 hours for full COREP/FINREP filing
GLOMIDCO Performance:
Parallel Processing:
├─ Process tables independently
├─ Distribute across multiple nodes
├─ Horizontal scaling possible
├─ Resource efficient (per-table memory)
├─ Fast feedback on individual tables
└─ Resilient to individual failures
Typical: 15-30 minutes for full COREP/FINREP filing
Performance: 5-10x faster with parallelization
¶ 5. Change Management
DPM Change Problems:
Regulatory Update Scenario:
EBA Updates: Table C 08.01 (Asset Encumbrance)
DPM Impact:
├─ Must modify monolithic mapping
├─ Risk breaking other tables (regression)
├─ Must test ALL 60+ tables again
├─ Cannot deploy partial updates
├─ High risk of cascade failures
└─ Long QA cycle (weeks/months)
Reality: Small change → Big risk → Delayed deployment
GLOMIDCO Change Benefits:
Regulatory Update Scenario:
EBA Updates: Table C 08.01 (Asset Encumbrance)
GLOMIDCO Impact:
├─ Modify ONLY C 08.01 mapping
├─ Zero impact on other tables (isolation)
├─ Test ONLY C 08.01 (quick)
├─ Deploy C 08.01 independently
├─ No regression risk
└─ Fast QA cycle (days)
Reality: Small change → Low risk → Fast deployment
¶ 6. Development and Testing
DPM Development Challenges:
Team Workflow:
├─ Multiple developers work on same monolithic mapping
├─ Merge conflicts common
├─ Cannot work in parallel effectively
├─ Testing requires full dataset
├─ Integration tests are slow
├─ Difficult to isolate test scenarios
└─ Long development cycles
Development Time: 12-18 months for full implementation
GLOMIDCO Development Advantages:
Team Workflow:
├─ Each developer owns specific tables
├─ No merge conflicts (separate mappings)
├─ Parallel development naturally
├─ Testing uses table-specific data
├─ Unit tests are fast
├─ Clear test boundaries
└─ Agile iterations possible
Development Time: 6-9 months for full implementation
Speed: 2x faster with better quality, nect reporting period, much can be re-used and potentially the next XBRL report will be much faster to create (unless the XBRL taxonomy has changed)
¶ 7. Data Lineage and Traceability
DPM Traceability Issues:
Question: "Where did this XBRL value come from?"
DPM Answer:
├─ Complex query through monolithic mapping
├─ Multiple transformation steps
├─ Difficult to trace backwards
├─ No clear audit trail
└─ Hours/days to answer
Auditor: "How was this calculated?"
You: "Uh... let me check the 50,000-line mapping file..."
GLOMIDCO Traceability:
Question: "Where did this XBRL value come from?"
GLOMIDCO Answer:
├─ Check table mapping (specific, small)
├─ Clear input → transform → output
├─ Per-fact lineage tracking
├─ Comprehensive audit trail
└─ Minutes to answer
Auditor: "How was this calculated?"
You: "Here's the table mapping, line 247, and here's the source data."
¶ 8. Reusability
DPM Reusability Problems:
Scenario: Need to generate quarterly AND annual reports
DPM:
├─ Duplicate entire monolithic mapping?
├─ Parameterize the massive transformation?
├─ Create variants (maintenance nightmare)?
└─ Reality: Copy-paste → Divergence → Inconsistency
Result: Multiple inconsistent versions
GLOMIDCO Reusability:
Scenario: Need to generate quarterly AND annual reports
GLOMIDCO:
├─ Reuse table mappings (same for both)
├─ Different orchestration (table selection)
├─ Parameter-driven execution
└─ Single source of truth
Result: One set of mappings, multiple uses
¶ 9. Debugging and Troubleshooting
DPM Debugging Nightmare:
Problem: Value in Table C 08.01 is incorrect
DPM Debugging:
├─ Load entire monolithic mapping
├─ Set breakpoints in 50,000+ line file
├─ Step through complex logic
├─ Navigate interdependencies
├─ Isolate specific calculation (difficult)
└─ Time: Hours/days
Developer: Pulls hair out
GLOMIDCO Debugging:
Problem: Value in Table C 08.01 is incorrect
GLOMIDCO Debugging:
├─ Open C 08.01 mapping (1,000 lines)
├─ Review table-specific logic
├─ Clear inputs and outputs
├─ Isolated transformation
├─ Easy to reproduce
└─ Time: Minutes/hours
Developer: Happy
¶ 10. Memory and Resource Usage
DPM Resource Consumption:
Monolithic Processing:
├─ Load ALL table definitions (GB)
├─ Load ALL business data (GB)
├─ Keep everything in memory
├─ Process serially (no release)
├─ Peak memory: 4-8 GB
└─ Cannot scale horizontally
Result: Requires expensive hardware
GLOMIDCO Resource Efficiency:
Distributed Processing:
├─ Load only needed table definition (MB)
├─ Load only needed business data (MB)
├─ Process and release
├─ Parallel processing across nodes
├─ Peak memory per table: 100-500 MB
└─ Horizontal scaling supported
Result: Runs on commodity hardware
¶ 11. Integration with Business Systems
DPM Integration Challenges:
Business System Integration:
├─ Must extract ALL data upfront (this costs a LOT of man hours, often from external accountancies)
├─ Single extraction batch job
├─ Long-running extract (hours)
├─ Large staging tables
├─ Complex ETL processes
└─ Fragile extraction logic
Result: Complex, brittle data pipeline
GLOMIDCO Integration:
Business System Integration:
├─ Extract data per table (incremental)
├─ On-demand extraction possible
├─ Short-running queries (minutes)
├─ Small staging (per-table)
├─ Simple, focused queries
└─ Resilient to source changes
Result: Flexible, robust data pipeline
📊 Comparison Summary
| Aspect | DPM Approach | GLOMIDCO Mapping |
|---|---|---|
| Architecture | Monolithic | Distributed |
| Complexity | High (60+ tables together) | Low (per-table) |
| Maintainability | Difficult | Easy |
| Error Isolation | Poor | Excellent |
| Recovery | All-or-nothing | Granular |
| Performance | Slow (2-4 hours) | Fast (15-30 min) |
| Scalability | Vertical only | Horizontal |
| Parallelization | No | Yes |
| Change Impact | High risk | Low risk |
| Testing | Slow, complex | Fast, simple |
| Development Time | 12-18 months | 6-9 months |
| Team Collaboration | Difficult | Easy |
| Debugging | Nightmare | Manageable |
| Memory Usage | 4-8 GB | 100-500 MB/table |
| Traceability | Poor | Excellent |
| Reusability | Low | High |
| Resource Cost | Expensive hardware | Commodity hardware |
🎯 Real-World Impact
DPM Reality:
Bank IT Team Experience:
├─ Initial estimate: 6 months
├─ Actual delivery: 18 months
├─ Maintenance: 2-3 FTE ongoing
├─ Change cycles: 3-6 months
├─ Production issues: Weekly
├─ Emergency fixes: Common
└─ Team morale: Low
Cost: High, Risk: High, Agility: Low
GLOMIDCO Reality:
Bank IT Team Experience:
├─ Initial estimate: 6 months
├─ Actual delivery: 7 months
├─ Maintenance: 0.5 FTE ongoing
├─ Change cycles: 1-2 weeks
├─ Production issues: Monthly
├─ Emergency fixes: Rare
└─ Team morale: High
Cost: Low, Risk: Low, Agility: High
✅ Why GLOMIDCO's Approach Wins
Core Principle: Divide and Conquer
GLOMIDCO Philosophy:
├─ Break complex problem into small pieces
├─ Solve each piece independently
├─ Assemble pieces into solution
├─ Isolate failures
├─ Enable parallelism
└─ Promote maintainability
Result: Manageable, scalable, maintainable system
The Mapping-Based Approach:
- Table-Level Granularity - Each table is an independent unit
- Clear Interfaces - Well-defined inputs and outputs
- Independent Processing - No cross-table dependencies
- Parallel Execution - Natural horizontal scaling
- Incremental Delivery - Partial success is valuable
- Fast Feedback - Quick iteration cycles
- Low Risk - Changes are isolated
- High Quality - Easier to test and validate
🎓 Lessons Learned
Why DPM Failed:
- Tried to solve everything at once (monolithic)
- Didn't account for operational realities
- Underestimated complexity
- Ignored human factors (maintainability)
- Focused on theoretical elegance over practical utility
Why GLOMIDCO Succeeds:
- Focused on operational realities first
- Designed for change from day one
- Prioritized maintainability and debuggability
- Enabled team collaboration naturally
- Balanced theoretical soundness with practical constraints
📚 Reference
For complete details, see Document 13: COREP-FINREP and Middleware Approach which covers:
COREP/FINREP complexity (60+ tables)
DPM limitations in detail
- GLOMIDCO's distributed middleware solution
- BPM/ESB integration architecture
- Real-world implementation experiences
- Performance benchmarks
- Cost-benefit analysis
Bottom Line: DPM is theoretically elegant but operationally impractical.
GLOMIDCO's mapping-based approach is pragmatic, scalable, and proven (from middleware perspective) in production for complex regulatory reporting